Predicting the ratings of reviews of a hotel using Machine Learning
Machine Learning (ML) is a field of Artificial Intelligence where data-driven algorithms learn patterns by getting exposed to relevant data. ML has gained massive importance in the field of Natural Language Processing (NLP), i.e. interpreting human language. In this article, we will focus on the use of ML in predicting the ratings of user reviews. The data used in this article was taken from Kaggle (Link) where around 20000 reviews were collected from Trip Advisor.
All the code in this article has been written in Python 3 using Jupyter Notebook.
To begin with, we must import the relevant libraries we will be using for this task.
import numpy as np
import pandas as pd
import re
import spacy
from nltk.corpus import stopwords
from wordcloud import WordCloud,STOPWORDS
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
import stringLet’s see some of the rows in the data.
data = pd.read_csv('input/trip-advisor-hotel-reviews/tripadvisor_hotel_reviews.csv')
data.head()
Let’s see a small description of the data.
data.describe()
As we can see, there are 20491 observations in the data. The mean rating is close to 4. Let’s see if there are any missing data.
data.isnull().mean()The output is as follows:
Review 0.0
Rating 0.0
dtype: float64Nice! No data is missing. Let’s see the number of unique ratings in the data.
data['Rating'].unique()The output is as follows:
array([4, 2, 3, 5, 1])We have only 5 unique values of the variable Rating. So we will treat this problem as a softmax classification problem. Formally, our task would be to train a model to classify a hotel review as 1,2,3,, or 5 stars.
Let’s see the distribution of each class within the table.
data['Rating'].value_counts(normalize=True)The output we get is:
5 0.441853
4 0.294715
3 0.106583
2 0.087502
1 0.069348
Name: Rating, dtype: float64We can see that most ratings are 5-star ratings and the least are 1-star ratings. Thus we must take care to train our model on enough 1-star ratings. Thus while training the data, we must stratify our dataset our data. This will ensure that the distribution of all the classes is even between the train, validation, and test set. This will help prevent unknown classes from appearing in the validation or test set.
We will now create a word cloud to see the most commonly occurring words in our reviews.
def wordCloud_generator(data, title=None):
wordcloud = WordCloud(width = 800, height = 800,
background_color ='black',
min_font_size = 10
).generate(" ".join(data.values))
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.tight_layout(pad = 0)
plt.title(title,fontsize=30)
plt.show()wordCloud_generator(data['Review'], title="Top words in reviews")

We will create copies of our data to preserve the original.
X = data['Review'].copy()
y = data['Rating'].copy()Textual data contains a lot of noise like stopwords (is, an, the, because, etc.) punctuation, different forms of the same word (like play, plays, playing, played, etc where the root word is play. This process is called lemmatization) and negation of words (like didn’t instead of did not). All of these interfere with the training process of our model and increase the vocabulary size of our model. So we must deal with them properly.
For this purpose, we will define a function to clean our data. To effectively do our preprocessing, we must have all our text in lower case. To handle negations we will use the apostrophe dictionary which has a of list all the frequently used apostrophe words in English. We can get it here. The dictionary is in lower case too.
On closer inspection of the data, we can observe that the data has misspelled words (shown below). For example “not” has been spelled as “n’t” in some cases and some negations liked “didn’t” have been spelled as “did n’t”. We shall address these inconsistencies in our cleaning process too.
"nice rooms not 4* experience hotel monaco seattle good hotel n't 4* level.positives large bathroom mediterranean suite comfortable bed pillowsattentive housekeeping staffnegatives ac unit malfunctioned stay desk disorganized, missed 3 separate wakeup calls, concierge busy hard touch, did n't provide guidance special requests.tv hard use ipod sound dock suite non functioning. decided book mediterranean suite 3 night weekend stay 1st choice rest party filled, comparison w spent 45 night larger square footage room great soaking tub whirlpool jets nice shower.before stay hotel arrange car service price 53 tip reasonable driver waiting arrival.checkin easy downside room picked 2 person jacuzi tub no bath accessories salts bubble bath did n't stay, night got 12/1a checked voucher bottle champagne nice gesture fish waiting room, impression room huge open space felt room big, tv far away bed chore change channel, ipod dock broken disappointing.in morning way asked desk check thermostat said 65f 74 2 degrees warm try cover face night bright blue light kept, got room night no, 1st drop desk, called maintainence came look thermostat told play settings happy digital box wo n't work, asked wakeup 10am morning did n't happen, called later 6pm nap wakeup forgot, 10am wakeup morning yep forgotten.the bathroom facilities great room surprised room sold whirlpool bath tub n't bath amenities, great relax water jets going, "
#sample review from the datasetThus, the apostrophe dictionary we got earlier, will be modified to account for this as follows:
apposV2 = {
"are not" : "are not",
"ca" : "can",
"could n't" : "could not",
"did n't" : "did not",
"does n't" : "does not",
"do n't" : "do not",
"had n't" : "had not",
"has n't" : "has not",
"have n't" : "have not",
"he'd" : "he would",
"he'll" : "he will",
"he's" : "he is",
"i'd" : "I would",
"i'd" : "I had",
"i'll" : "I will",
"i'm" : "I am",
"is n't" : "is not",
"it's" : "it is",
"it'll":"it will",
"i've" : "I have",
"let's" : "let us",
"might n't" : "might not",
"must n't" : "must not",
"sha" : "shall",
"she'd" : "she would",
"she'll" : "she will",
"she's" : "she is",
"should n't" : "should not",
"that's" : "that is",
"there's" : "there is",
"they'd" : "they would",
"they'll" : "they will",
"they're" : "they are",
"they've" : "they have",
"we'd" : "we would",
"we're" : "we are",
"were n't" : "were not",
"we've" : "we have",
"what'll" : "what will",
"what're" : "what are",
"what's" : "what is",
"what've" : "what have",
"where's" : "where is",
"who'd" : "who would",
"who'll" : "who will",
"who're" : "who are",
"who's" : "who is",
"who've" : "who have",
"wo" : "will",
"would n't" : "would not",
"you'd" : "you would",
"you'll" : "you will",
"you're" : "you are",
"you've" : "you have",
"'re": " are",
"was n't": "was not",
"we'll":"we will",
"did n't": "did not"
}appos = {
"aren't" : "are not",
"can't" : "cannot",
"couldn't" : "could not",
"didn't" : "did not",
"doesn't" : "does not",
"don't" : "do not",
"hadn't" : "had not",
"hasn't" : "has not",
"haven't" : "have not",
"he'd" : "he would",
"he'll" : "he will",
"he's" : "he is",
"i'd" : "I would",
"i'd" : "I had",
"i'll" : "I will",
"i'm" : "I am",
"isn't" : "is not",
"it's" : "it is",
"it'll":"it will",
"i've" : "I have",
"let's" : "let us",
"mightn't" : "might not",
"mustn't" : "must not",
"shan't" : "shall not",
"she'd" : "she would",
"she'll" : "she will",
"she's" : "she is",
"shouldn't" : "should not",
"that's" : "that is",
"there's" : "there is",
"they'd" : "they would",
"they'll" : "they will",
"they're" : "they are",
"they've" : "they have",
"we'd" : "we would",
"we're" : "we are",
"weren't" : "were not",
"we've" : "we have",
"what'll" : "what will",
"what're" : "what are",
"what's" : "what is",
"what've" : "what have",
"where's" : "where is",
"who'd" : "who would",
"who'll" : "who will",
"who're" : "who are",
"who's" : "who is",
"who've" : "who have",
"won't" : "will not",
"wouldn't" : "would not",
"you'd" : "you would",
"you'll" : "you will",
"you're" : "you are",
"you've" : "you have",
"'re": " are",
"wasn't": "was not",
"we'll":" will",
"didn't": "did not"
}
We will now set up our cleaning function.
nlp = spacy.load('en',disable=['parser','ner'])
stop = stopwords.words('english')
def cleanData(reviews):
all_=[]
for review in reviews:
lower_case = review.lower() #lower case the text
lower_case = lower_case.replace(" n't"," not") #correct n't as not
lower_case = lower_case.replace("."," . ")
lower_case = ' '.join(word.strip(string.punctuation) for word in lower_case.split()) #remove punctuation
words = lower_case.split() #split into words
words = [word for word in words if word.isalpha()] #remove numbers
split = [apposV2[word] if word in apposV2 else word for word in words] #correct using apposV2 as mentioned above
split = [appos[word] if word in appos else word for word in split] #correct using appos as mentioned above
split = [word for word in split if word not in stop] #remove stop words
reformed = " ".join(split) #join words back to the text
doc = nlp(reformed)
reformed = " ".join([token.lemma_ for token in doc]) #lemmatiztion
all_.append(reformed)
df_cleaned = pd.DataFrame()
df_cleaned['clean_reviews'] = all_
return df_cleaned['clean_reviews']X_cleaned = cleanData(X)
X_cleaned.head()
We get the following output:
0 nice hotel expensive parking get good deal sta...
1 ok nothing special charge diamond member hilto...
2 nice room experience hotel monaco seattle good...
3 unique great stay wonderful time hotel monaco ...
4 great stay great stay go seahawk game awesome ...
Name: clean_reviews, dtype: objectWe will also encode our target variable Rating, into a one hot vector.
encoding = {1: 0,
2: 1,
3: 2,
4: 3,
5: 4
}labels = ['1', '2', '3', '4', '5']
y = data['Rating'].copy()
y.replace(encoding, inplace=True)
y = to_categorical(y,5)
It’s time to split our data into train and test sets. We will use 80% of the data for training, 10% for validation, and 10% for testing.
X_train, X_test, y_train, y_test = train_test_split(X_cleaned, y, stratify=y, random_state=42,test_size=0.1)
#validation split will done when fitting the modelML models can’t make sense of text data. To feed them text data, we convert our text into sequences that be fed to the model. Keras provides a function for this very purpose. It creates a vocabulary of words and assigns each word an index that is used to represent the word in its sequence notation. Each sentence may not be the same length as the others. We pad them using Keras as our model expects each sentence to be of the same length.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequencestokenizer = Tokenizer()
tokenizer.fit_on_texts(X_train)X_train = tokenizer.texts_to_sequences(X_train)max_length = max([len(x) for x in X_train])
vocab_size = len(tokenizer.word_index)+1 #add 1 to account for unknown wordprint("Vocabulary size: {}".format(vocab_size))
print("Max length of sentence: {}".format(max_length))X_train = pad_sequences(X_train, max_length ,padding='post')
We get the following output:
Vocabulary size: 41115
Max length of sentence: 1800An important note here is to never fit the Tokenizer above on the validation or testing data. It must be fit ONLY on the training data. As a general note, any kind of fitting must be done only on the training data.
It’s time to start modeling. Let’s create our model. We will create a sequential model.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM,Dense,Dropout
from tensorflow.keras.layers import Bidirectional,Embedding,Flatten
from tensorflow.keras.callbacks import EarlyStopping,ModelCheckpointembedding_vector_length=32
num_classes = 5
model = Sequential()model.add(Embedding(vocab_size,embedding_vector_length,input_length=X_train.shape[1]))
model.add(Bidirectional(LSTM(250,return_sequences=True)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128,activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(64,activation='relu'))
model.add(Dense(32,activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(16,activation='relu'))
model.add(Dense(num_classes,activation='softmax'))model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])callbacks = [EarlyStopping(monitor='val_loss', patience=5),
ModelCheckpoint('../model/model.h5', save_best_only=True,
save_weights_only=False)]
model.summary()
We add some dropout layers and callbacks to prevent overfitting. We get the following output.
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 1800, 32) 1315680
_________________________________________________________________
bidirectional_1 (Bidirection (None, 1800, 500) 566000
_________________________________________________________________
dropout_3 (Dropout) (None, 1800, 500) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 900000) 0
_________________________________________________________________
dense_5 (Dense) (None, 128) 115200128
_________________________________________________________________
dropout_4 (Dropout) (None, 128) 0
_________________________________________________________________
dense_6 (Dense) (None, 64) 8256
_________________________________________________________________
dense_7 (Dense) (None, 32) 2080
_________________________________________________________________
dropout_5 (Dropout) (None, 32) 0
_________________________________________________________________
dense_8 (Dense) (None, 16) 528
_________________________________________________________________
dense_9 (Dense) (None, 5) 85
=================================================================
Total params: 117,092,757
Trainable params: 117,092,757
Non-trainable params: 0
_________________________________________________________________Let’s fit our model and start the training process.
history = model.fit(X_train, y_train, validation_split=0.11,
epochs=15, batch_size=32, verbose=1,
callbacks=callbacks)Our training yields the following results.
Epoch 1/15
513/513 [==============================] - 195s 368ms/step - loss: 1.6616 - accuracy: 0.4265 - val_loss: 0.9994 - val_accuracy: 0.5002
Epoch 2/15
513/513 [==============================] - 189s 369ms/step - loss: 0.9146 - accuracy: 0.5659 - val_loss: 0.9282 - val_accuracy: 0.5619
Epoch 3/15
513/513 [==============================] - 188s 367ms/step - loss: 0.7914 - accuracy: 0.6282 - val_loss: 0.9804 - val_accuracy: 0.5722
Epoch 4/15
513/513 [==============================] - 189s 368ms/step - loss: 0.6786 - accuracy: 0.7044 - val_loss: 0.9794 - val_accuracy: 0.6077
Epoch 5/15
513/513 [==============================] - 189s 368ms/step - loss: 0.5620 - accuracy: 0.7673 - val_loss: 1.0368 - val_accuracy: 0.5973
Epoch 6/15
513/513 [==============================] - 188s 367ms/step - loss: 0.4566 - accuracy: 0.8180 - val_loss: 1.2449 - val_accuracy: 0.5875
Epoch 7/15
513/513 [==============================] - 189s 369ms/step - loss: 0.3666 - accuracy: 0.8607 - val_loss: 1.3929 - val_accuracy: 0.5954We can notice that the model stopped with 7 epochs although it was set for 15 epochs. This is because of our callback. It stopped the training process as soon as it observed that there was no improvement in the validation accuracy after 5 epochs. Additionally, it also saved the weights of the model which best prevent overfitting.
We reached an accuracy of 60% on the validation set and 70% on our train set (4th epoch). We can reduce the overfitting further by increasing the Dropout layers. Let’s plot our results.
import matplotlib.pyplot as plt
plt.plot(history.history['loss'], label='Training')
plt.plot(history.history['val_loss'], label='Validation')
plt.legend()
plt.title('Training and Validation Loss')
plt.figure()
plt.plot(history.history['accuracy'],label='Training')
plt.plot(history.history['val_accuracy'],label='Validation')
plt.legend()
plt.title('Training and Validation accuracy')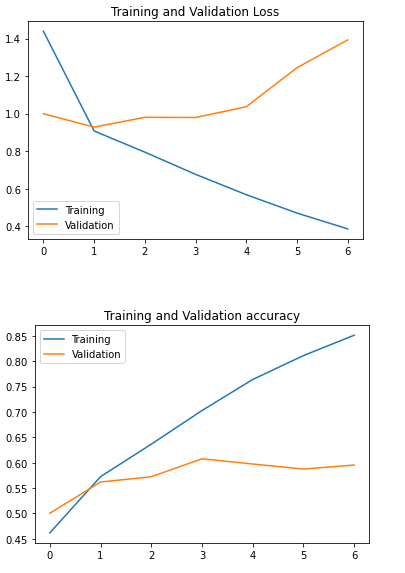
Let’s do some predictions on our test set.
X_test_token = tokenizer.texts_to_sequences(X_test)
X_test_token = pad_sequences(X_test_token, max_length ,padding='post')
pred = model.predict(X_test_token)
pred = to_categorical(pred,5)We can get the accuracy score and the classification report as follows:
from sklearn.metrics import classification_report,accuracy_score
print('Test Accuracy: {}'.format(accuracy_score(pred, y_test)))
print(classification_report(y_test, pred, target_names=labels))The output is follows:
Test Accuracy: 0.5936585365853658 precision recall f1-score support
1 0.61 0.64 0.63 142
2 0.40 0.31 0.35 179
3 0.45 0.32 0.38 219
4 0.47 0.57 0.52 604
5 0.75 0.72 0.73 906
micro avg 0.59 0.59 0.59 2050
macro avg 0.54 0.51 0.52 2050
weighted avg 0.59 0.59 0.59 2050
samples avg 0.59 0.59 0.59 2050
From our classification report, we can observe that our model performs reasonably well on 1,4 and 5-star ratings and relatively bad on 2 and 3-star ratings. To improve the performance, we can inspect the 2 and 3-star reviews more closely. We can also implement other preprocessing techniques like Stemming instead of Lemmatization and see how it affects performance.
That’s it for this article. See you later!

